
You know that feeling when a website takes forever to load and you just close it? Exactly—that’s how your users feel when your system fails. Therefore, SREs obsess over cloud SRE metrics. In today’s cloud-driven world, reliability isn’t just a nice-to-have; it’s the backbone of user trust. The good news is that by tracking the right metrics, you can spot issues early, prevent outages, and keep your systems running smoothly. Next, let’s break down the key cloud SRE metrics every team should monitor.
Why Metrics Matter for Cloud SREs
Running cloud systems without metrics is like driving at night with no streetlights—you have no idea what’s coming. In fact, metrics help SREs spot problems early, decide when to scale, and keep services running smoothly. If you don’t measure it, then you can’t improve it.
Users expect apps to work instantly. As a result, every second of downtime or lag costs trust. Therefore, tracking the right metrics isn’t optional—it’s how you keep your systems reliable and your users happy.
The Golden Signals: The Four Must-Monitor Metrics
SREs often talk about the ‘Golden Signals.’ These are the four key metrics that give you the clearest picture of your system’s health. Think of them as your system’s vital signs.
- Latency – “How fast is your system responding? Slow responses frustrate users, so keeping an eye on latency is a must.”
- Traffic – “How much load is hitting your system? Sudden spikes—like during a big sale—can break unprepared services.”
- Errors – “Things go wrong. Tracking errors tells you what’s broken and helps you fix it before users notice.”
- Saturation – “This measures how ‘stressed’ your system is. High CPU, memory, or disk usage can signal trouble before it turns into downtime.”
By watching these four signals, you can catch issues early, prevent outages, and keep your users happy. Later, we’ll see how SLIs, SLOs, and error budgets tie into all of this.
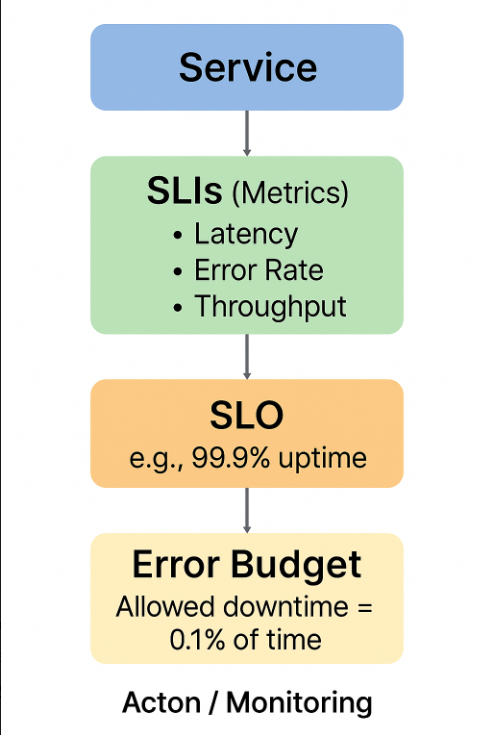
SLIs, SLOs, and Error Budgets
- SLIs (Service Level Indicators): The actual measurements of your system’s health—like latency, traffic, errors, and saturation.
- SLOs (Service Level Objectives): The reliability goals you set based on SLIs (e.g., 99.9% uptime).
- Error Budgets: The “wiggle room” for failure. If your SLO is 99.9%, your error budget is the 0.1% downtime you can afford.
Together, they create a balance:
- SLIs tell you what’s happening.
- SLOs tell you what should happen.
- Error Budgets tell you how much risk you can take.
Why Metrics Are the Backbone of Cloud Reliability
In the cloud, nothing stays still for long. One moment your app is handling normal traffic, and the next a sudden spike—maybe from a flash sale or a trending post—pushes your system to its limits. Add in microservices, containers, and serverless functions, and you’ve got a complex web that’s constantly shifting.
This is where metrics come in. They’re not just numbers on a dashboard; they’re the lifeline of your cloud systems. Metrics give you the visibility you need to understand what’s happening right now and the confidence to act before things break.
- Traffic can spike anytime. Metrics like latency and saturation tell you when it’s time to scale.
- Distributed systems are tricky. With dozens of services working together, metrics help you trace issues back to the real cause.
- Reliability is shared. Cloud providers keep the infrastructure up, but it’s on us to make sure the application experience meets user expectations.
- Innovation needs guardrails. Error budgets let us ship new features quickly without sacrificing reliability.
At the end of the day, metrics are the backbone of reliability in the cloud. They help us stay ahead of problems, balance speed with stability, and, most importantly, keep users happy.
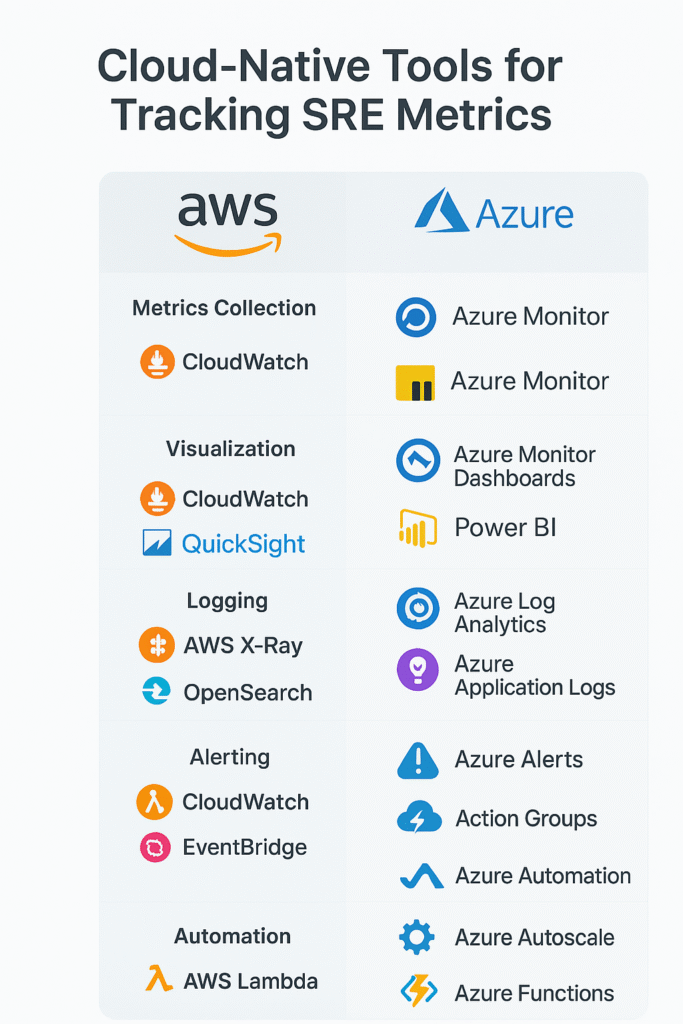
Tools & Practices for Tracking SRE Metrics
Final Thoughts on SRE Metrics
In today’s cloud-first world, reliability isn’t a nice-to-have—it’s the foundation of user trust. By tracking the right metrics, defining SLOs, and using cloud-native tools, teams can stay ahead of failures, balance speed with stability, and deliver experiences users can count on. In the end, metrics aren’t just numbers—they’re the heartbeat of cloud reliability.