
You know that moment when everything’s running smoothly — deployments are green, dashboards look perfect — and then bam! an alert pops up on your phone at 2 a.m.?
Yeah, every DevOps or SRE engineer has been there.
Incidents happen — whether it’s a failed deployment, a sudden spike in traffic, or even a cloud service outage. What really matters isn’t just how fast you fix it, but how scalable and reliable your incident management system is when problems start happening all at once.
In the cloud, where your infrastructure can grow faster than you can blink, managing incidents manually or with tools that don’t work well together just doesn’t cut it anymore. You need a system that can detect, respond, and even self-heal, no matter how big your environment gets.
What Makes Incident Management Scalable?
So, what does it actually mean for an incident management system to be scalable?
Imagine this: your app is handling 1,000 users per day, and everything works fine. Then suddenly, you launch a new feature, traffic spikes to 100,000 users, and alerts start flooding in. If your incident management system can’t keep up, you and your team will be drowning in notifications — trying to figure out what’s important, what’s urgent, and what can wait.
A scalable incident management system is one that can:
- Handle more alerts without breaking a sweat – it filters, prioritizes, and routes issues automatically.
- Work across multiple systems and services – not just your main app, but databases, APIs, cloud services, and microservices too.
- Automate responses when possible – so small problems get fixed before they even reach your inbox.
- Keep your team coordinated – ensuring the right people are alerted at the right time, without noise or confusion.
In short, scalability isn’t just about surviving high traffic or multiple alerts. It’s about keeping your system smart, fast, and reliable no matter how big your cloud environment grows.
Core Components of a Cloud-Based Incident Management System
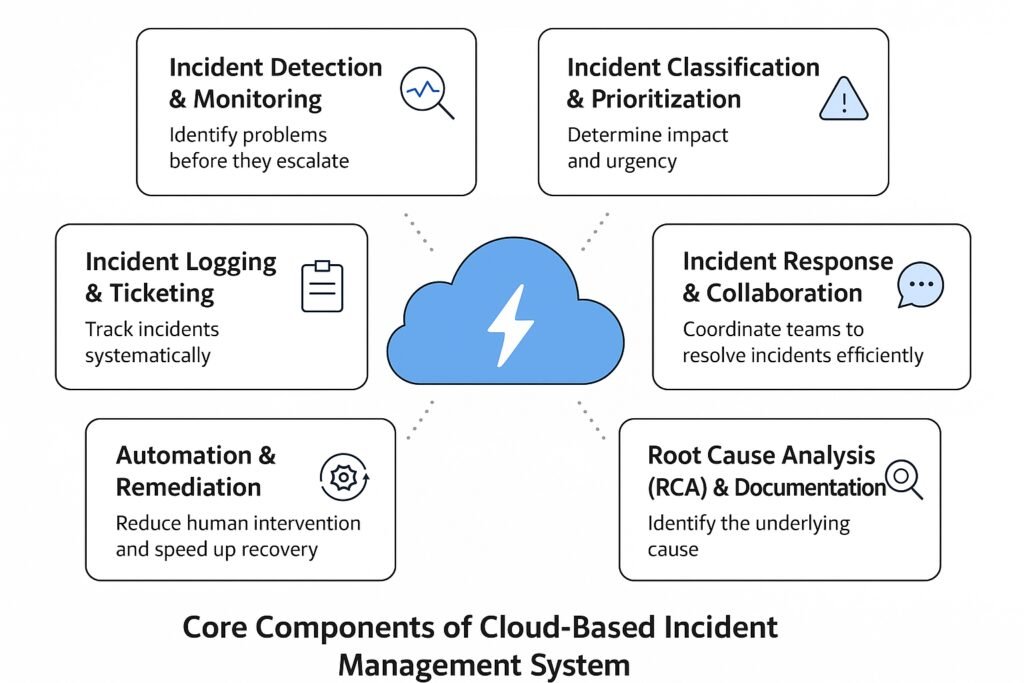
Designing for Scalability
Alright, now that we know the core components, let’s talk about scaling them. Because in the cloud, “just enough” today can be “completely overwhelmed” tomorrow.
Microservices-based incident management is a smart approach. By breaking your system into smaller, independent services, each piece can scale independently. So, if one service starts getting slammed with alerts, the rest of your system stays steady.
Then there’s event-driven architecture. Using serverless components like AWS Lambda or Azure Functions, your system can react instantly to incidents without having servers idling around, waiting for something to happen. Combine that with distributed alerting and auto-remediation, and your system can not only detect problems but also start fixing them automatically.
And don’t forget Infrastructure as Code (IaC). Tools like Terraform or ARM templates let you spin up environments consistently and quickly. Scaling isn’t scary when your infrastructure is reproducible and version-controlled.
Automation and AI in Incident Management
Here’s where it gets fun. Automation and AI aren’t just buzzwords—they actually make life easier.
ChatOps lets your team interact with your systems right from chat apps like Slack or Teams. Need to restart a service? Trigger a runbook? Do it without leaving your chat window.
Predictive incident detection uses machine learning to spot potential problems before they even happen. Imagine your system waving a hand: “Hey, something might break here soon!”
And then there are automated runbooks. With tools like Ansible, Terraform, or Azure Automation, you can predefine responses to incidents. Small problems get fixed automatically, leaving your team to focus on the tricky stuff.
Best Practices for Scalable Incident Management
- Set Clear Goals (SLOs/SLAs & Error Budgets) – Know what “good performance” means for your system. Define clear targets and acceptable limits so your team knows when to take action — and when to breathe easy.
- Centralize Your Monitoring and Logs – Keep all your metrics, logs, and alerts in one place. When something breaks, you shouldn’t have to dig through five dashboards to find the issue.
- Make Alerts Actionable – Don’t let your team drown in notifications. Send alerts only when they matter and make sure each one points to a clear next step.
- Automate and Document – Automate repetitive fixes where you can — and for the rest, keep simple, step-by-step runbooks. It saves time when every minute counts.
- Encourage a Blameless Culture – When things go wrong, focus on learning, not blaming. Every incident should make your system stronger and your team smarter.
Real-World Example
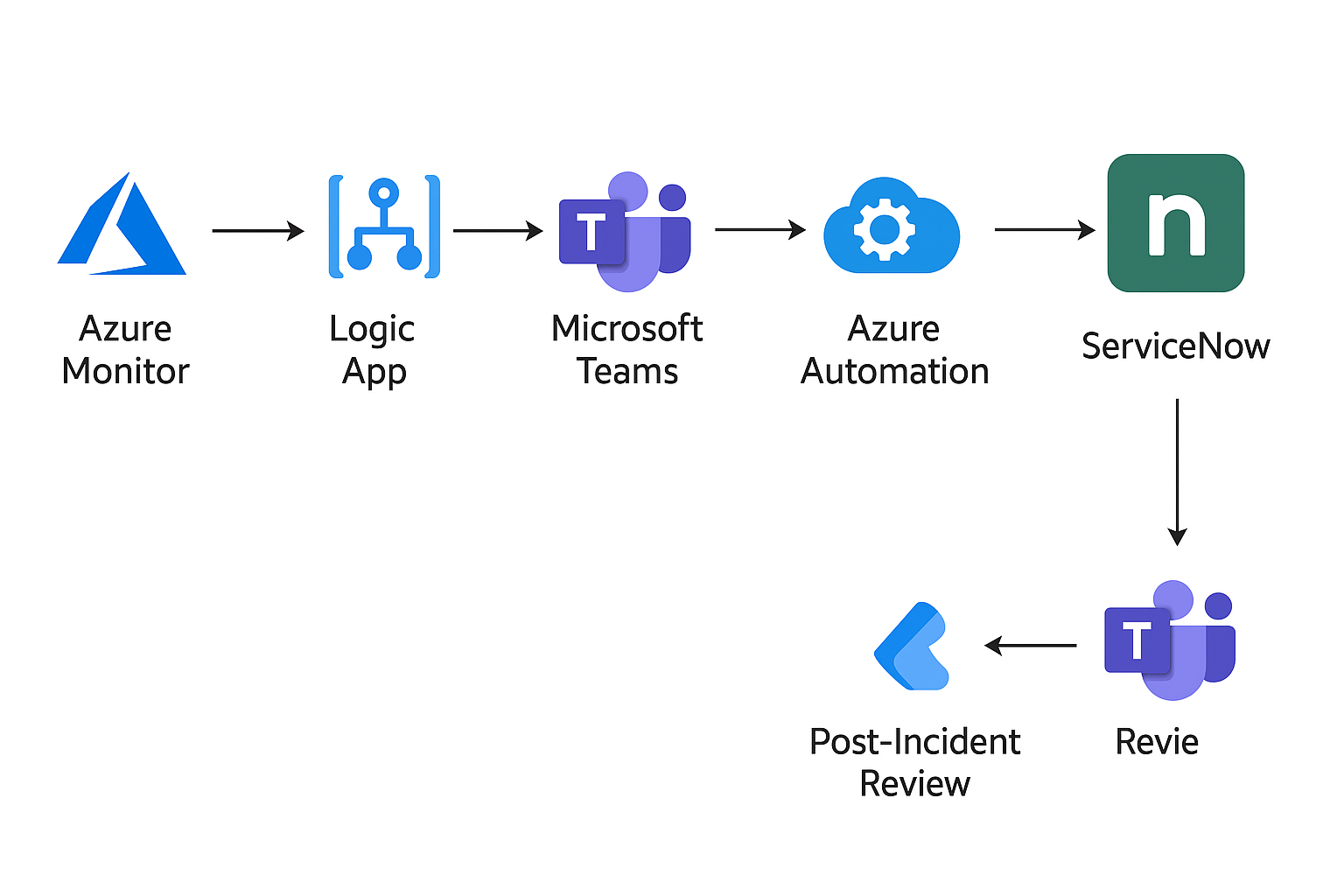
Let’s walk through what’s happening in the diagram above — step by step:
- Azure Monitor – Detects the Issue
Azure Monitor keeps an eye on all your applications and infrastructure. The moment it notices something unusual (like high latency, failed transactions, or CPU spikes), it triggers an alert rule. - Logic App – Starts the Automation Flow
That alert doesn’t just send an email — it kicks off a Logic App workflow. Think of this as the automation brain that decides what happens next. It could notify people, create tickets, or call another service automatically. - Microsoft Teams – Notifies the On-Call Team
The Logic App then sends an alert message directly into Microsoft Teams. The on-call engineer gets instant visibility — no need to check dashboards or emails. Everyone can collaborate right inside the chat. - Azure Automation – Runs Auto-Remediation
In parallel, Azure Automation takes action. It might restart a virtual machine, roll back a deployment, or restart a container in AKS — whatever your predefined runbook says to do. - ServiceNow – Tracks the Incident
The same Logic App also creates a ticket in ServiceNow, ensuring the incident is properly tracked and documented from start to finish. - Post-Incident Review – Learn and Improve
Once the issue is resolved, the workflow triggers a Post-Incident Review in Teams. The team can discuss what happened, update runbooks, and make the system even more resilient next time.
Conclusion
At the end of the day, incidents are unavoidable — but chaos doesn’t have to be.
A scalable, automated incident management system turns panic into process. By combining cloud-native tools like Azure Monitor, Logic Apps, Automation, and Teams, you can detect issues faster, respond automatically, and learn from every incident without burning out your team.
The real win isn’t just fixing problems — it’s improving your MTTR (Mean Time to Recovery), keeping customers happy, and giving your engineers their sleep back.
Building a scalable system isn’t about avoiding failure; it’s about handling it gracefully — at any scale. So, start small, automate smartly, and keep evolving your process. Because in the world of cloud reliability, continuous improvement is the ultimate uptime strategy.